- Adds a core-owned realtime backend prompt template and preparation
path.
- Makes omitted realtime start prompts use the core default, while null
or empty prompts intentionally send empty instructions.
- Covers the core realtime path and app-server v2 path with integration
coverage.
---------
Co-authored-by: Codex <noreply@openai.com>
Summary:
- parse the realtime call Location header and join that call over the
direct realtime WebSocket
- keep WebRTC starts alive on the existing realtime conversation path
Validation:
- just fmt
- git diff --check
- cargo check -p codex-api
- cargo check -p codex-core --tests
- local cargo tests not run; relying on PR CI
Fast Mode status was still tied to one model name in the TUI and
model-list plumbing. This changes the model metadata shape so a model
can advertise additional speed tiers, carries that field through the
app-server model list, and uses it to decide when to show Fast Mode
status.
For people using Codex, the behavior is intended to stay the same for
existing models. Fast Mode still requires the existing signed-in /
feature-gated path; the difference is that the UI can now recognize any
model the model list marks as Fast-capable, instead of requiring a new
client-side slug check.
Adds WebRTC startup to the experimental app-server
`thread/realtime/start` method with an optional transport enum. The
websocket path remains the default; WebRTC offers create the realtime
session through the shared start flow and emit the answer SDP via
`thread/realtime/sdp`.
---------
Co-authored-by: Codex <noreply@openai.com>
Addresses #16244
This was a performance regression introduced when we moved the TUI on
top of the app server API.
Problem: `/mcp` rebuilt a full MCP inventory through
`mcpServerStatus/list`, including resources and resource templates that
made the TUI wait on slow inventory probes.
Solution: add a lightweight `detail` mode to `mcpServerStatus/list`,
have `/mcp` request tools-and-auth only, and cover the fast path with
app-server and TUI tests.
Testing: Confirmed slow (multi-second) response prior to change and
immediate response after change.
I considered two options:
1. Change the existing `mcpServerStatus/list` API to accept an optional
"details" parameter so callers can request only a subset of the
information.
2. Add a separate `mcpServer/list` API that returns only the servers,
tools, and auth but omits the resources.
I chose option 1, but option 2 is also a reasonable approach.
### Summary
Fix `thread/metadata/update` so it can still patch stored thread
metadata when the list/backfill-gated `get_state_db(...)` path is
unavailable.
What was happening:
- The app logs showed `thread/metadata/update` failing with `sqlite
state db unavailable for thread ...`.
- This was not isolated to one bad thread. Once the failure started for
a user, branch metadata updates failed 100% of the time for that user.
- Reports were staggered across users, which points at local app-server
/ local SQLite state rather than one global server-side failure.
- Turns could still start immediately after the metadata update failed,
which suggests the thread itself was valid and the failure was in the
metadata endpoint DB-handle path.
The fix:
- Keep using the loaded thread state DB and the normal
`get_state_db(...)` fallback first.
- If that still returns `None`, open `StateRuntime::init(...)` directly
for this targeted metadata update path.
- Log the direct state runtime init error if that final fallback also
fails, so future reports have the real DB-open cause instead of only the
generic unavailable error.
- Add a regression test where the DB exists but backfill is not
complete, and verify `thread/metadata/update` can still repair the
stored rollout thread and patch `gitInfo`.
Relevant context / suspect PRs:
- #16434 changed state DB startup to run auto-vacuum / incremental
vacuum. This is the most suspicious timing match for per-user, staggered
local SQLite availability failures.
- #16433 dropped the old log table from the state DB, also near the
timing window.
- #13280 introduced this endpoint and made it rely on SQLite for git
metadata without resuming the thread.
- #14859 and #14888 added/consumed persisted model + reasoning effort
metadata. I checked these because of the new thread metadata fields, but
this failure happens before the endpoint reaches thread-row update/load
logic, so they seem less likely as the direct cause.
### Testing
- `cargo fmt -- --config imports_granularity=Item` completed; local
stable rustfmt emitted warnings that `imports_granularity` is unstable
- `cargo test -p codex-app-server thread_metadata_update`
- `git diff --check`
## Why
Extracted from [#16528](https://github.com/openai/codex/pull/16528) so
the Windows Bazel app-server test failures can be reviewed independently
from the rest of that PR.
This PR targets:
-
`suite::v2::thread_shell_command::thread_shell_command_runs_as_standalone_turn_and_persists_history`
-
`suite::v2::thread_start::thread_start_with_elevated_sandbox_trusts_project_and_followup_loads_project_config`
-
`suite::v2::thread_start::thread_start_with_nested_git_cwd_trusts_repo_root`
There were two Windows-specific assumptions baked into those tests and
the underlying trust lookup:
- project trust keys were persisted and looked up using raw path
strings, but Bazel's Windows test environment can surface canonicalized
paths with `\\?\` / UNC prefixes or normalized symlink/junction targets,
so follow-up `thread/start` requests no longer matched the project entry
that had just been written
- `item/commandExecution/outputDelta` assertions compared exact trailing
line endings even though shell output chunk boundaries and CRLF handling
can differ on Windows, and Bazel made that timing-sensitive mismatch
visible
There was also one behavior bug separate from the assertion cleanup:
`thread/start` decided whether to persist trust from the final resolved
sandbox policy, but on Windows an explicit `workspace-write` request may
be downgraded to `read-only`. That incorrectly skipped writing trust
even though the request had asked to elevate the project, so the new
logic also keys off the requested sandbox mode.
## What
- Canonicalize project trust keys when persisting/loading `[projects]`
entries, while still accepting legacy raw keys for existing configs.
- Persist project trust when `thread/start` explicitly requests
`workspace-write` or `danger-full-access`, even if the resolved policy
is later downgraded on Windows.
- Make the Windows app-server tests compare persisted trust paths and
command output deltas in a path/newline-normalized way.
## Verification
- Existing app-server v2 tests cover the three failing Windows Bazel
cases above.
Addresses #16671 and #14927
Problem: `mcpServerStatus/list` rebuilt MCP tool groups from sanitized
tool prefixes but looked them up by unsanitized server names, so
hyphenated servers rendered as having no tools in `/mcp`. This was
reported as a regression when the TUI switched to use the app server.
Solution: Build each server's tool map using the original server name's
sanitized prefix, include effective runtime MCP servers in the status
response, and add a regression test for hyphenated server names.
## Why
`thread/shellCommand` executes the raw command string through the
current user shell, which is PowerShell on Windows. The two v2
app-server tests in `app-server/tests/suite/v2/thread_shell_command.rs`
used POSIX `printf`, so Bazel CI on Windows failed with `printf` not
being recognized as a PowerShell command.
For reference, the user-shell task wraps commands with the active shell
before execution:
[`core/src/tasks/user_shell.rs`](7a3eec6fdb/codex-rs/core/src/tasks/user_shell.rs (L120-L126)).
## What Changed
Added a test-local helper that builds a shell-appropriate output command
and expected newline sequence from `default_user_shell()`:
- PowerShell: `Write-Output '...'` with `\r\n`
- Cmd: `echo ...` with `\r\n`
- POSIX shells: `printf '%s\n' ...` with `\n`
Both `thread_shell_command_runs_as_standalone_turn_and_persists_history`
and `thread_shell_command_uses_existing_active_turn` now use that
helper.
## Verification
- `cargo test -p codex-app-server thread_shell_command`
- Persist trusted cwd state during thread/start when the resolved
sandbox is elevated.
- Add app-server coverage for trusted root resolution and confirm
turn/start does not mutate trust.
Addresses #16560
Problem: `/status` stopped showing the source thread id in forked TUI
sessions after the app-server migration.
Solution: Carry fork source ids through app-server v2 thread data and
the TUI session adapter, and update TUI fixtures so `/status` matches
the old TUI behavior.
## Why
This finishes the config-type move out of `codex-core` by removing the
temporary compatibility shim in `codex_core::config::types`. Callers now
depend on `codex-config` directly, which keeps these config model types
owned by the config crate instead of re-expanding `codex-core` as a
transitive API surface.
## What Changed
- Removed the `codex-rs/core/src/config/types.rs` re-export shim and the
`core::config::ApprovalsReviewer` re-export.
- Updated `codex-core`, `codex-cli`, `codex-tui`, `codex-app-server`,
`codex-mcp-server`, and `codex-linux-sandbox` call sites to import
`codex_config::types` directly.
- Added explicit `codex-config` dependencies to downstream crates that
previously relied on the `codex-core` re-export.
- Regenerated `codex-rs/core/config.schema.json` after updating the
config docs path reference.
## Why
`codex-core` was re-exporting APIs owned by sibling `codex-*` crates,
which made downstream crates depend on `codex-core` as a proxy module
instead of the actual owner crate.
Removing those forwards makes crate boundaries explicit and lets leaf
crates drop unnecessary `codex-core` dependencies. In this PR, this
reduces the dependency on `codex-core` to `codex-login` in the following
files:
```
codex-rs/backend-client/Cargo.toml
codex-rs/mcp-server/tests/common/Cargo.toml
```
## What
- Remove `codex-rs/core/src/lib.rs` re-exports for symbols owned by
`codex-login`, `codex-mcp`, `codex-rollout`, `codex-analytics`,
`codex-protocol`, `codex-shell-command`, `codex-sandboxing`,
`codex-tools`, and `codex-utils-path`.
- Delete the `default_client` forwarding shim in `codex-rs/core`.
- Update in-crate and downstream callsites to import directly from the
owning `codex-*` crate.
- Add direct Cargo dependencies where callsites now target the owner
crate, and remove `codex-core` from `codex-rs/backend-client`.
Makes fuzzy file search use case-insensitive matching instead of
smart-case in `codex-file-search`. I find smart-case to be a poor user
experience -using the wrong case for a letter drops its match so
significantly, it often drops off the results list, effectively making a
search case-sensitive.
## Why
`argument-comment-lint` was green in CI even though the repo still had
many uncommented literal arguments. The main gap was target coverage:
the repo wrapper did not force Cargo to inspect test-only call sites, so
examples like the `latest_session_lookup_params(true, ...)` tests in
`codex-rs/tui_app_server/src/lib.rs` never entered the blocking CI path.
This change cleans up the existing backlog, makes the default repo lint
path cover all Cargo targets, and starts rolling that stricter CI
enforcement out on the platform where it is currently validated.
## What changed
- mechanically fixed existing `argument-comment-lint` violations across
the `codex-rs` workspace, including tests, examples, and benches
- updated `tools/argument-comment-lint/run-prebuilt-linter.sh` and
`tools/argument-comment-lint/run.sh` so non-`--fix` runs default to
`--all-targets` unless the caller explicitly narrows the target set
- fixed both wrappers so forwarded cargo arguments after `--` are
preserved with a single separator
- documented the new default behavior in
`tools/argument-comment-lint/README.md`
- updated `rust-ci` so the macOS lint lane keeps the plain wrapper
invocation and therefore enforces `--all-targets`, while Linux and
Windows temporarily pass `-- --lib --bins`
That temporary CI split keeps the stricter all-targets check where it is
already cleaned up, while leaving room to finish the remaining Linux-
and Windows-specific target-gated cleanup before enabling
`--all-targets` on those runners. The Linux and Windows failures on the
intermediate revision were caused by the wrapper forwarding bug, not by
additional lint findings in those lanes.
## Validation
- `bash -n tools/argument-comment-lint/run.sh`
- `bash -n tools/argument-comment-lint/run-prebuilt-linter.sh`
- shell-level wrapper forwarding check for `-- --lib --bins`
- shell-level wrapper forwarding check for `-- --tests`
- `just argument-comment-lint`
- `cargo test` in `tools/argument-comment-lint`
- `cargo test -p codex-terminal-detection`
## Follow-up
- Clean up remaining Linux-only target-gated callsites, then switch the
Linux lint lane back to the plain wrapper invocation.
- Clean up remaining Windows-only target-gated callsites, then switch
the Windows lint lane back to the plain wrapper invocation.
## Problem
App-server clients could only initiate ChatGPT login through the browser
callback flow, even though the shared login crate already supports
device-code auth. That left VS Code, Codex App, and other app-server
clients without a first-class way to use the existing device-code
backend when browser redirects are brittle or when the client UX wants
to own the login ceremony.
## Mental model
This change adds a second ChatGPT login start path to app-server:
clients can now call `account/login/start` with `type:
"chatgptDeviceCode"`. App-server immediately returns a `loginId` plus
the device-code UX payload (`verificationUrl` and `userCode`), then
completes the login asynchronously in the background using the existing
`codex_login` polling flow. Successful device-code login still resolves
to ordinary `chatgpt` auth, and completion continues to flow through the
existing `account/login/completed` and `account/updated` notifications.
## Non-goals
This does not introduce a new auth mode, a new account shape, or a
device-code eligibility discovery API. It also does not add automatic
fallback to browser login in core; clients remain responsible for
choosing when to request device code and whether to retry with a
different UX if the backend/admin policy rejects it.
## Tradeoffs
We intentionally keep `login_chatgpt_common` as a local validation
helper instead of turning it into a capability probe. Device-code
eligibility is checked by actually calling `request_device_code`, which
means policy-disabled cases surface as an immediate request error rather
than an async completion event. We also keep the active-login state
machine minimal: browser and device-code logins share the same public
cancel contract, but device-code cancellation is implemented with a
local cancel token rather than a larger cross-crate refactor.
## Architecture
The protocol grows a new `chatgptDeviceCode` request/response variant in
app-server v2. On the server side, the new handler reuses the existing
ChatGPT login precondition checks, calls `request_device_code`, returns
the device-code payload, and then spawns a background task that waits on
either cancellation or `complete_device_code_login`. On success, it
reuses the existing auth reload and cloud-requirements refresh path
before emitting `account/login/completed` success and `account/updated`.
On failure or cancellation, it emits only `account/login/completed`
failure. The existing `account/login/cancel { loginId }` contract
remains unchanged and now works for both browser and device-code
attempts.
## Tests
Added protocol serialization coverage for the new request/response
variant, plus app-server tests for device-code success, failure, cancel,
and start-time rejection behavior. Existing browser ChatGPT login
coverage remains in place to show that the callback-based flow is
unchanged.
## Summary
This change adds websocket authentication at the app-server transport
boundary and enforces it before JSON-RPC `initialize`, so authenticated
deployments reject unauthenticated clients during the websocket
handshake rather than after a connection has already been admitted.
During rollout, websocket auth is opt-in for non-loopback listeners so
we do not break existing remote clients. If `--ws-auth ...` is
configured, the server enforces auth during websocket upgrade. If auth
is not configured, non-loopback listeners still start, but app-server
logs a warning and the startup banner calls out that auth should be
configured before real remote use.
The server supports two auth modes: a file-backed capability token, and
a standard HMAC-signed JWT/JWS bearer token verified with the
`jsonwebtoken` crate, with optional issuer, audience, and clock-skew
validation. Capability tokens are normalized, hashed, and compared in
constant time. Short shared secrets for signed bearer tokens are
rejected at startup. Requests carrying an `Origin` header are rejected
with `403` by transport middleware, and authenticated clients present
credentials as `Authorization: Bearer <token>` during websocket upgrade.
## Validation
- `cargo test -p codex-app-server transport::auth`
- `cargo test -p codex-cli app_server_`
- `cargo clippy -p codex-app-server --all-targets -- -D warnings`
- `just bazel-lock-check`
Note: in the broad `cargo test -p codex-app-server
connection_handling_websocket` run, the touched websocket auth cases
passed, but unrelated Unix shutdown tests failed with a timeout in this
environment.
---------
Co-authored-by: Eric Traut <etraut@openai.com>
### Summary
Add the v2 app-server filesystem watch RPCs and notifications, wire them
through the message processor, and implement connection-scoped watches
with notify-backed change delivery. This also updates the schema
fixtures, app-server documentation, and the v2 integration coverage for
watch and unwatch behavior.
This allows clients to efficiently watch for filesystem updates, e.g. to
react on branch changes.
### Testing
- exercise watch lifecycles for directory changes, atomic file
replacement, missing-file targets, and unwatch cleanup
- create `codex-git-utils` and move the shared git helpers into it with
file moves preserved for diff readability
- move the `GitInfo` helpers out of `core` so stacked rollout work can
depend on the shared crate without carrying its own git info module
---------
Co-authored-by: Ahmed Ibrahim <219906144+aibrahim-oai@users.noreply.github.com>
Co-authored-by: Codex <noreply@openai.com>
## Why
`shell-tool-mcp` and the Bash fork are no longer needed, but the patched
zsh fork is still relevant for shell escalation and for the
DotSlash-backed zsh-fork integration tests.
Deleting the old `shell-tool-mcp` workflow also deleted the only
pipeline that rebuilt those patched zsh binaries. This keeps the package
removal, while preserving a small release path that can be reused
whenever `codex-rs/shell-escalation/patches/zsh-exec-wrapper.patch`
changes.
## What changed
- removed the `shell-tool-mcp` workspace package, its npm
packaging/release jobs, the Bash test fixture, and the remaining
Bash-specific compatibility wiring
- deleted the old `.github/workflows/shell-tool-mcp.yml` and
`.github/workflows/shell-tool-mcp-ci.yml` workflows now that their
responsibilities have been replaced or removed
- kept the zsh patch under
`codex-rs/shell-escalation/patches/zsh-exec-wrapper.patch` and updated
the `codex-rs/shell-escalation` docs/code to describe the zsh-based flow
directly
- added `.github/workflows/rust-release-zsh.yml` to build only the three
zsh binaries that `codex-rs/app-server/tests/suite/zsh` needs today:
- `aarch64-apple-darwin` on `macos-15`
- `x86_64-unknown-linux-musl` on `ubuntu-24.04`
- `aarch64-unknown-linux-musl` on `ubuntu-24.04`
- extracted the shared zsh build/smoke-test/stage logic into
`.github/scripts/build-zsh-release-artifact.sh`, made that helper
directly executable, and now invoke it directly from the workflow so the
Linux and macOS jobs only keep the OS-specific setup in YAML
- wired those standalone `codex-zsh-*.tar.gz` assets into
`rust-release.yml` and added `.github/dotslash-zsh-config.json` so
releases also publish a `codex-zsh` DotSlash file
- updated the checked-in `codex-rs/app-server/tests/suite/zsh` fixture
comments to explain that new releases come from the standalone zsh
assets, while the checked-in fixture remains pinned to the latest
historical release until a newer zsh artifact is published
- tightened a couple of follow-on cleanups in
`codex-rs/shell-escalation`: the `ExecParams::command` comment now
describes the shell `-c`/`-lc` string more clearly, and the README now
points at the same `git.code.sf.net` zsh source URL that the workflow
uses
## Testing
- `cargo test -p codex-shell-escalation`
- `just argument-comment-lint`
- `bash -n .github/scripts/build-zsh-release-artifact.sh`
- attempted `cargo test -p codex-core`; unrelated existing failures
remain, but the touched `tools::runtimes::shell::unix_escalation::*`
coverage passed during that run
built from #14256. PR description from @etraut-openai:
This PR addresses a hole in [PR
11802](https://github.com/openai/codex/pull/11802). The previous PR
assumed that app server clients would respond to token refresh failures
by presenting the user with an error ("you must log in again") and then
not making further attempts to call network endpoints using the expired
token. While they do present the user with this error, they don't
prevent further attempts to call network endpoints and can repeatedly
call `getAuthStatus(refreshToken=true)` resulting in many failed calls
to the token refresh endpoint.
There are three solutions I considered here:
1. Change the getAuthStatus app server call to return a null auth if the
caller specified "refreshToken" on input and the refresh attempt fails.
This will cause clients to immediately log out the user and return them
to the log in screen. This is a really bad user experience. It's also a
breaking change in the app server contract that could break third-party
clients.
2. Augment the getAuthStatus app server call to return an additional
field that indicates the state of "token could not be refreshed". This
is a non-breaking change to the app server API, but it requires
non-trivial changes for all clients to properly handle this new field
properly.
3. Change the getAuthStatus implementation to handle the case where a
token refresh fails by marking the AuthManager's in-memory access and
refresh tokens as "poisoned" so it they are no longer used. This is the
simplest fix that requires no client changes.
I chose option 3.
Here's Codex's explanation of this change:
When an app-server client asks `getAuthStatus(refreshToken=true)`, we
may try to refresh a stale ChatGPT access token. If that refresh fails
permanently (for example `refresh_token_reused`, expired, or revoked),
the old behavior was bad in two ways:
1. We kept the in-memory auth snapshot alive as if it were still usable.
2. Later auth checks could retry refresh again and again, creating a
storm of doomed `/oauth/token` requests and repeatedly surfacing the
same failure.
This is especially painful for app-server clients because they poll auth
status and can keep driving the refresh path without any real chance of
recovery.
This change makes permanent refresh failures terminal for the current
managed auth snapshot without changing the app-server API contract.
What changed:
- `AuthManager` now poisons the current managed auth snapshot in memory
after a permanent refresh failure, keyed to the unchanged `AuthDotJson`.
- Once poisoned, later refresh attempts for that same snapshot fail fast
locally without calling the auth service again.
- The poison is cleared automatically when auth materially changes, such
as a new login, logout, or reload of different auth state from storage.
- `getAuthStatus(includeToken=true)` now omits `authToken` after a
permanent refresh failure instead of handing out the stale cached bearer
token.
This keeps the current auth method visible to clients, avoids forcing an
immediate logout flow, and stops repeated refresh attempts for
credentials that cannot recover.
---------
Co-authored-by: Eric Traut <etraut@openai.com>
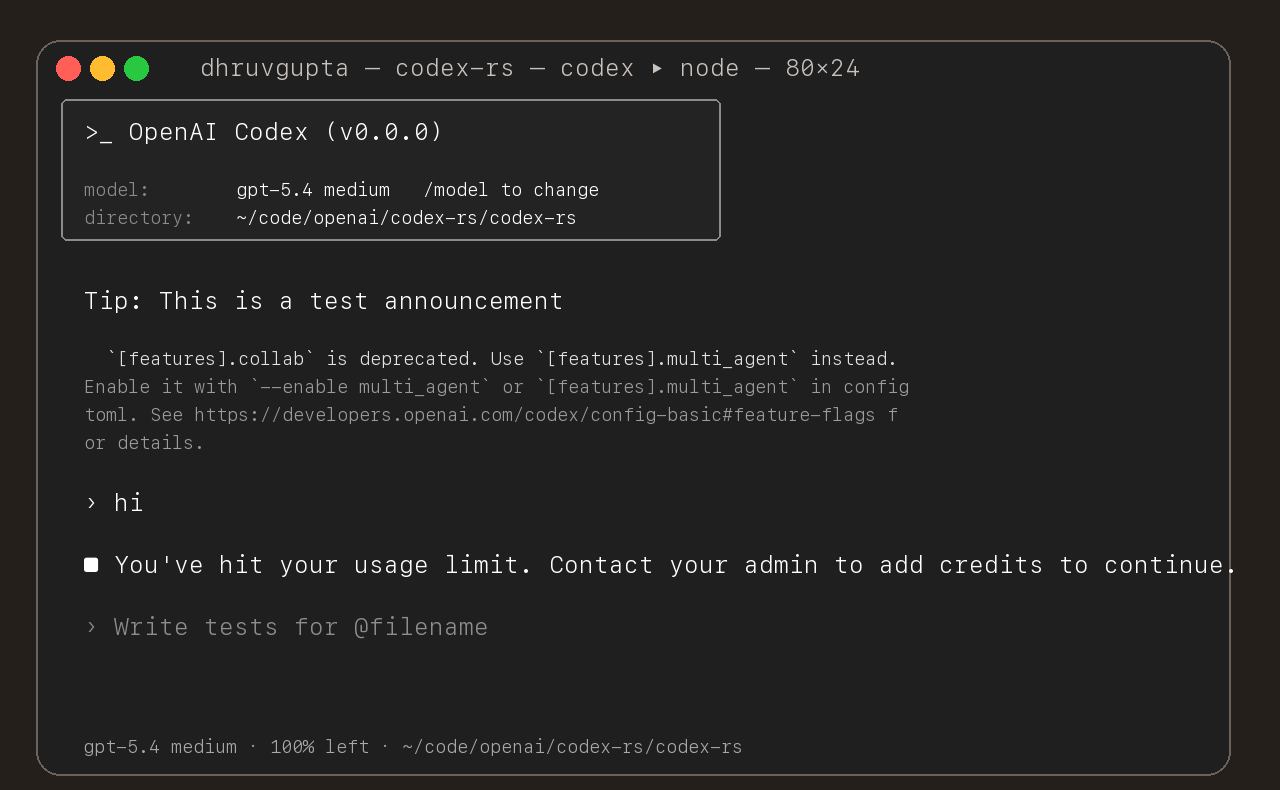
## Summary
- update the self-serve business usage-based limit message to direct
users to their admin for additional credits
- add a focused unit test for the self_serve_business_usage_based plan
branch
Added also:
If you are at a rate limit but you still have credits, codex cli would
tell you to switch the model. We shouldnt do this if you have credits so
fixed this.
## Test
- launched the source-built CLI and verified the updated message is
shown for the self-serve business usage-based plan
## Summary
- add `ForkSnapshotMode` to `ThreadManager::fork_thread` so callers can
request either a committed snapshot or an interrupted snapshot
- share the model-visible `<turn_aborted>` history marker between the
live interrupt path and interrupted forks
- update the small set of direct fork callsites to pass
`ForkSnapshotMode::Committed`
Note: this enables /btw to work similarly as Esc to interrupt (hopefully
somewhat in distribution)
---------
Co-authored-by: Codex <noreply@openai.com>
- emit a typed `thread/realtime/transcriptUpdated` notification from
live realtime transcript deltas
- expose that notification as flat `threadId`, `role`, and `text` fields
instead of a nested transcript array
- continue forwarding raw `handoff_request` items on
`thread/realtime/itemAdded`, including the accumulated
`active_transcript`
- update app-server docs, tests, and generated protocol schema artifacts
to match the delta-based payloads
---------
Co-authored-by: Codex <noreply@openai.com>
This PR add an URI-based system to reference agents within a tree. This
comes from a sync between research and engineering.
The main agent (the one manually spawned by a user) is always called
`/root`. Any sub-agent spawned by it will be `/root/agent_1` for example
where `agent_1` is chosen by the model.
Any agent can contact any agents using the path.
Paths can be used either in absolute or relative to the calling agents
Resume is not supported for now on this new path
- Split the feature system into a new `codex-features` crate.
- Cut `codex-core` and workspace consumers over to the new config and
warning APIs.
Co-authored-by: Ahmed Ibrahim <219906144+aibrahim-oai@users.noreply.github.com>
Co-authored-by: Codex <noreply@openai.com>
{kind=link}