### Summary
Add the v2 app-server filesystem watch RPCs and notifications, wire them
through the message processor, and implement connection-scoped watches
with notify-backed change delivery. This also updates the schema
fixtures, app-server documentation, and the v2 integration coverage for
watch and unwatch behavior.
This allows clients to efficiently watch for filesystem updates, e.g. to
react on branch changes.
### Testing
- exercise watch lifecycles for directory changes, atomic file
replacement, missing-file targets, and unwatch cleanup
## Summary
- drop `sandbox_permissions` from the sandboxing `ExecOptions` and
`ExecRequest` adapter types
- remove the now-unused plumbing from shell, unified exec, JS REPL, and
apply-patch runtime call sites
- default reconstructed `ExecParams` to `SandboxPermissions::UseDefault`
where the lower-level API still requires the field
## Testing
- `just fmt`
- `just argument-comment-lint`
- `cargo test -p codex-core` (still running locally; first failures
observed in `suite::cli_stream::responses_mode_stream_cli`,
`suite::cli_stream::responses_mode_stream_cli_supports_openai_base_url_config_override`,
and
`suite::cli_stream::responses_mode_stream_cli_supports_openai_base_url_env_fallback`)
Switch plugin-install background MCP OAuth to a silent login path so the
raw authorization URL is no longer printed in normal success cases.
OAuth behavior is otherwise unchanged, with fallback URL output via
stderr still shown only if browser launch fails.
Before:
https://github.com/user-attachments/assets/4bf387af-afa8-4b83-bcd6-4ca6b55da8db
## Summary
Fixes slow `Ctrl+C` exit from the ChatGPT browser-login screen in
`tui_app_server`.
## Root cause
Onboarding-level `Ctrl+C` quit bypassed the auth widget's cancel path.
That let the active ChatGPT login keep running, and in-process
app-server shutdown then waited on the stale login attempt before
finishing.
## Changes
- Extract a shared `cancel_active_attempt()` path in the auth widget
- Use that path from onboarding-level `Ctrl+C` before exiting the TUI
- Add focused tests for canceling browser-login and device-code attempts
- Add app-server shutdown cleanup that explicitly drops any active login
before draining background work
- create `codex-git-utils` and move the shared git helpers into it with
file moves preserved for diff readability
- move the `GitInfo` helpers out of `core` so stacked rollout work can
depend on the shared crate without carrying its own git info module
---------
Co-authored-by: Ahmed Ibrahim <219906144+aibrahim-oai@users.noreply.github.com>
Co-authored-by: Codex <noreply@openai.com>
## Why
`shell-tool-mcp` and the Bash fork are no longer needed, but the patched
zsh fork is still relevant for shell escalation and for the
DotSlash-backed zsh-fork integration tests.
Deleting the old `shell-tool-mcp` workflow also deleted the only
pipeline that rebuilt those patched zsh binaries. This keeps the package
removal, while preserving a small release path that can be reused
whenever `codex-rs/shell-escalation/patches/zsh-exec-wrapper.patch`
changes.
## What changed
- removed the `shell-tool-mcp` workspace package, its npm
packaging/release jobs, the Bash test fixture, and the remaining
Bash-specific compatibility wiring
- deleted the old `.github/workflows/shell-tool-mcp.yml` and
`.github/workflows/shell-tool-mcp-ci.yml` workflows now that their
responsibilities have been replaced or removed
- kept the zsh patch under
`codex-rs/shell-escalation/patches/zsh-exec-wrapper.patch` and updated
the `codex-rs/shell-escalation` docs/code to describe the zsh-based flow
directly
- added `.github/workflows/rust-release-zsh.yml` to build only the three
zsh binaries that `codex-rs/app-server/tests/suite/zsh` needs today:
- `aarch64-apple-darwin` on `macos-15`
- `x86_64-unknown-linux-musl` on `ubuntu-24.04`
- `aarch64-unknown-linux-musl` on `ubuntu-24.04`
- extracted the shared zsh build/smoke-test/stage logic into
`.github/scripts/build-zsh-release-artifact.sh`, made that helper
directly executable, and now invoke it directly from the workflow so the
Linux and macOS jobs only keep the OS-specific setup in YAML
- wired those standalone `codex-zsh-*.tar.gz` assets into
`rust-release.yml` and added `.github/dotslash-zsh-config.json` so
releases also publish a `codex-zsh` DotSlash file
- updated the checked-in `codex-rs/app-server/tests/suite/zsh` fixture
comments to explain that new releases come from the standalone zsh
assets, while the checked-in fixture remains pinned to the latest
historical release until a newer zsh artifact is published
- tightened a couple of follow-on cleanups in
`codex-rs/shell-escalation`: the `ExecParams::command` comment now
describes the shell `-c`/`-lc` string more clearly, and the README now
points at the same `git.code.sf.net` zsh source URL that the workflow
uses
## Testing
- `cargo test -p codex-shell-escalation`
- `just argument-comment-lint`
- `bash -n .github/scripts/build-zsh-release-artifact.sh`
- attempted `cargo test -p codex-core`; unrelated existing failures
remain, but the touched `tools::runtimes::shell::unix_escalation::*`
coverage passed during that run
built from #14256. PR description from @etraut-openai:
This PR addresses a hole in [PR
11802](https://github.com/openai/codex/pull/11802). The previous PR
assumed that app server clients would respond to token refresh failures
by presenting the user with an error ("you must log in again") and then
not making further attempts to call network endpoints using the expired
token. While they do present the user with this error, they don't
prevent further attempts to call network endpoints and can repeatedly
call `getAuthStatus(refreshToken=true)` resulting in many failed calls
to the token refresh endpoint.
There are three solutions I considered here:
1. Change the getAuthStatus app server call to return a null auth if the
caller specified "refreshToken" on input and the refresh attempt fails.
This will cause clients to immediately log out the user and return them
to the log in screen. This is a really bad user experience. It's also a
breaking change in the app server contract that could break third-party
clients.
2. Augment the getAuthStatus app server call to return an additional
field that indicates the state of "token could not be refreshed". This
is a non-breaking change to the app server API, but it requires
non-trivial changes for all clients to properly handle this new field
properly.
3. Change the getAuthStatus implementation to handle the case where a
token refresh fails by marking the AuthManager's in-memory access and
refresh tokens as "poisoned" so it they are no longer used. This is the
simplest fix that requires no client changes.
I chose option 3.
Here's Codex's explanation of this change:
When an app-server client asks `getAuthStatus(refreshToken=true)`, we
may try to refresh a stale ChatGPT access token. If that refresh fails
permanently (for example `refresh_token_reused`, expired, or revoked),
the old behavior was bad in two ways:
1. We kept the in-memory auth snapshot alive as if it were still usable.
2. Later auth checks could retry refresh again and again, creating a
storm of doomed `/oauth/token` requests and repeatedly surfacing the
same failure.
This is especially painful for app-server clients because they poll auth
status and can keep driving the refresh path without any real chance of
recovery.
This change makes permanent refresh failures terminal for the current
managed auth snapshot without changing the app-server API contract.
What changed:
- `AuthManager` now poisons the current managed auth snapshot in memory
after a permanent refresh failure, keyed to the unchanged `AuthDotJson`.
- Once poisoned, later refresh attempts for that same snapshot fail fast
locally without calling the auth service again.
- The poison is cleared automatically when auth materially changes, such
as a new login, logout, or reload of different auth state from storage.
- `getAuthStatus(includeToken=true)` now omits `authToken` after a
permanent refresh failure instead of handing out the stale cached bearer
token.
This keeps the current auth method visible to clients, avoids forcing an
immediate logout flow, and stops repeated refresh attempts for
credentials that cannot recover.
---------
Co-authored-by: Eric Traut <etraut@openai.com>
* Add
`OutgoingMessageSender::send_server_notification_to_connection_and_wait`
which returns only once message is written to websocket (or failed to do
so)
* Use this mechanism to apply back pressure to stdout/stderr streams of
processes spawned by `command/exec`, to limit them to at most one
message in-memory at a time
* Use back pressure signal to also batch smaller chunks into ≈64KiB ones
This should make commands execution more robust over
high-latency/low-throughput networks
This PR completes the conversion of non-interactive `codex exec` to use
app server rather than directly using core events and methods.
### Summary
- move `codex-exec` off exec-owned `AuthManager` and `ThreadManager`
state
- route exec bootstrap, resume, and auth refresh through existing
app-server paths
- replace legacy `codex/event/*` decoding in exec with typed app-server
notification handling
- update human and JSONL exec output adapters to translate existing
app-server notifications only
- clean up "app server client" layer by eliminating support for legacy
notifications; this is no longer needed
- remove exposure of `authManager` and `threadManager` from "app server
client" layer
### Testing
- `exec` has pretty extensive unit and integration tests already, and
these all pass
- In addition, I asked Codex to put together a comprehensive manual set
of tests to cover all of the `codex exec` functionality (including
command-line options), and it successfully generated and ran these tests
## Summary
- move the pure sandbox policy transform helpers from `codex-core` into
`codex-sandboxing`
- move the corresponding unit tests with the extracted implementation
- update `core` and `app-server` callers to import the moved APIs
directly, without re-exports or proxy methods
## Testing
- cargo test -p codex-sandboxing
- cargo test -p codex-core sandboxing
- cargo test -p codex-app-server --lib
- just fix -p codex-sandboxing
- just fix -p codex-core
- just fix -p codex-app-server
- just fmt
- just argument-comment-lint
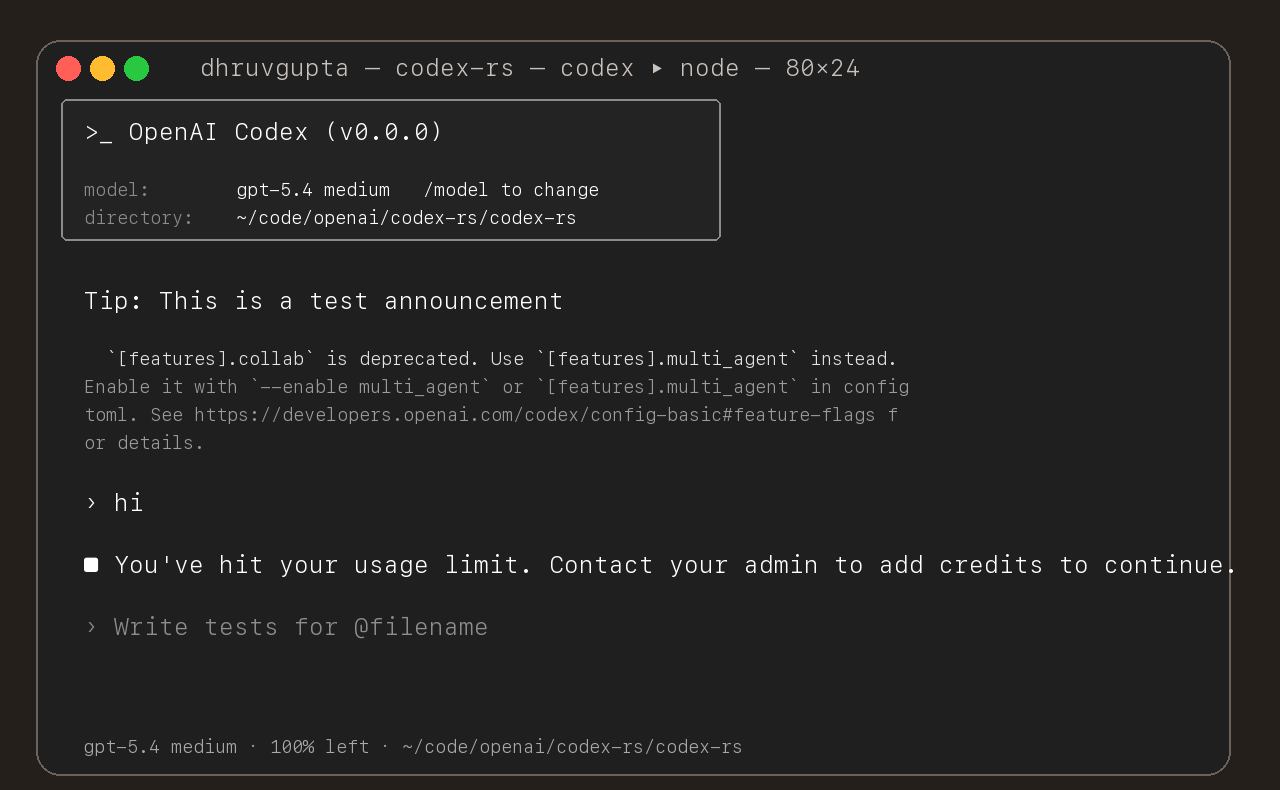
## Summary
- update the self-serve business usage-based limit message to direct
users to their admin for additional credits
- add a focused unit test for the self_serve_business_usage_based plan
branch
Added also:
If you are at a rate limit but you still have credits, codex cli would
tell you to switch the model. We shouldnt do this if you have credits so
fixed this.
## Test
- launched the source-built CLI and verified the updated message is
shown for the self-serve business usage-based plan
## Summary
- add `ForkSnapshotMode` to `ThreadManager::fork_thread` so callers can
request either a committed snapshot or an interrupted snapshot
- share the model-visible `<turn_aborted>` history marker between the
live interrupt path and interrupted forks
- update the small set of direct fork callsites to pass
`ForkSnapshotMode::Committed`
Note: this enables /btw to work similarly as Esc to interrupt (hopefully
somewhat in distribution)
---------
Co-authored-by: Codex <noreply@openai.com>
## Summary
- queue input after the user submits `/compact` until that manual
compact turn ends
- mirror the same behavior in the app-server TUI
- add regressions for input queued before compact starts and while it is
running
Co-authored-by: Codex <noreply@openai.com>
## Why
Fixes [#15283](https://github.com/openai/codex/issues/15283), where
sandboxed tool calls fail on older distro `bubblewrap` builds because
`/usr/bin/bwrap` does not understand `--argv0`. The upstream [bubblewrap
v0.9.0 release
notes](https://github.com/containers/bubblewrap/releases/tag/v0.9.0)
explicitly call out `Add --argv0`. Flipping `use_legacy_landlock`
globally works around that compatibility bug, but it also weakens the
default Linux sandbox and breaks proxy-routed and split-policy cases
called out in review.
The follow-up Linux CI failure was in the new launcher test rather than
the launcher logic: the fake `bwrap` helper stayed open for writing, so
Linux would not exec it. This update also closes the user-visibility gap
from review by surfacing the same startup warning when `/usr/bin/bwrap`
is present but too old for `--argv0`, not only when it is missing.
## What Changed
- keep `use_legacy_landlock` default-disabled
- teach `codex-rs/linux-sandbox/src/launcher.rs` to fall back to the
vendored bubblewrap build when `/usr/bin/bwrap` does not advertise
`--argv0` support
- add launcher tests for supported, unsupported, and missing system
`bwrap`
- write the fake `bwrap` test helper to a closed temp path so the
supported-path launcher test works on Linux too
- extend the startup warning path so Codex warns when `/usr/bin/bwrap`
is missing or too old to support `--argv0`
- mirror the warning/fallback wording across
`codex-rs/linux-sandbox/README.md` and `codex-rs/core/README.md`,
including that the fallback is the vendored bubblewrap compiled into the
binary
- cite the upstream `bubblewrap` release that introduced `--argv0`
## Verification
- `bazel test --config=remote --platforms=//:rbe
//codex-rs/linux-sandbox:linux-sandbox-unit-tests
--test_filter=launcher::tests::prefers_system_bwrap_when_help_lists_argv0
--test_output=errors`
- `cargo test -p codex-core system_bwrap_warning`
- `cargo check -p codex-exec -p codex-tui -p codex-tui-app-server -p
codex-app-server`
- `just argument-comment-lint`
- emit a typed `thread/realtime/transcriptUpdated` notification from
live realtime transcript deltas
- expose that notification as flat `threadId`, `role`, and `text` fields
instead of a nested transcript array
- continue forwarding raw `handoff_request` items on
`thread/realtime/itemAdded`, including the accumulated
`active_transcript`
- update app-server docs, tests, and generated protocol schema artifacts
to match the delta-based payloads
---------
Co-authored-by: Codex <noreply@openai.com>
This PR add an URI-based system to reference agents within a tree. This
comes from a sync between research and engineering.
The main agent (the one manually spawned by a user) is always called
`/root`. Any sub-agent spawned by it will be `/root/agent_1` for example
where `agent_1` is chosen by the model.
Any agent can contact any agents using the path.
Paths can be used either in absolute or relative to the calling agents
Resume is not supported for now on this new path
## Summary
- make app-server treat `clientInfo.name == "codex-tui"` as a legacy
compatibility case
- fall back to `DEFAULT_ORIGINATOR` instead of sending `codex-tui` as
the originator header
- add a TODO noting this is a temporary workaround that should be
removed later
## Testing
- Not run (not requested)
- Split the feature system into a new `codex-features` crate.
- Cut `codex-core` and workspace consumers over to the new config and
warning APIs.
Co-authored-by: Ahmed Ibrahim <219906144+aibrahim-oai@users.noreply.github.com>
Co-authored-by: Codex <noreply@openai.com>
- Move the auth implementation and token data into codex-login.
- Keep codex-core re-exporting that surface from codex-login for
existing callers.
---------
Co-authored-by: Codex <noreply@openai.com>
For each feature we have:
1. Trait exposed on environment
2. **Local Implementation** of the trait
3. Remote implementation that uses the client to proxy via network
4. Handler implementation that handles PRC requests and calls into
**Local Implementation**
## Summary
Persist Stop-hook continuation prompts as `user` messages instead of
hidden `developer` messages + some requested integration tests
This is a followup to @pakrym 's comment in
https://github.com/openai/codex/pull/14532 to make sure stop-block
continuation prompts match training for turn loops
- Stop continuation now writes `<hook_prompt hook_run_id="...">stop
hook's user prompt<hook_prompt>`
- Introduces quick-xml dependency, though we already indirectly depended
on it anyway via syntect
- This PR only has about 500 lines of actual logic changes, the rest is
tests/schema
## Testing
Example run (with a sessionstart hook and 3 stop hooks) - this shows
context added by session start, then two stop hooks sending their own
additional prompts in a new turn. The model responds with a single
message addressing both. Then when that turn ends, the hooks detect that
they just ran using `stop_hook_active` and decide not to infinite loop
test files for this (unzip, move codex -> .codex):
[codex.zip](https://github.com/user-attachments/files/26075806/codex.zip)
```
› cats
• Running SessionStart hook: lighting the observatory
SessionStart hook (completed)
warning: Hi, I'm a session start hook for wizard-tower (startup).
hook context: A wimboltine stonpet is an exotic cuisine from hyperspace
• Cats are tiny zen wizards, my friend: equal parts nap, mystery, and chaos. If you want, we can talk
cat facts, cat breeds, cat names, or build something cat-themed in this repo.
• Running Stop hook: checking the tower wards
• Running Stop hook: sacking the guards
• Running Stop hook: hiring the guards
Stop hook (completed)
warning: Wizard Tower Stop hook reviewed the completed reply (177 chars).
Stop hook (blocked)
warning: Wizard Tower Stop hook continuing conversation
feedback: cook the stonpet
Stop hook (blocked)
warning: Wizard Tower Stop hook continuing conversation
feedback: eat the cooked stonpet
• Stonpet’s cooked, aloha style: flash-seared over a blue quasiflame, glazed with nebula salt, and
rested until the hyperspace juices settle.
Now we eat with gratitude, my friend. One mindful bite in, and the flavor is pure cosmic surf:
smoky, bright, and totally out of this dimension.
• Running Stop hook: checking the tower wards
• Running Stop hook: sacking the guards
• Running Stop hook: hiring the guards
Stop hook (completed)
warning: Wizard Tower Stop hook reviewed the completed reply (285 chars).
Stop hook (completed)
warning: Wizard Tower Stop hook saw a second pass and stayed calm to avoid a loop.
Stop hook (completed)
warning: Wizard Tower Stop hook saw a second pass and stayed calm to avoid a loop.
```
The idea is that codex-exec exposes an Environment struct with services
on it. Each of those is a trait.
Depending on construction parameters passed to Environment they are
either backed by local or remote server but core doesn't see these
differences.
1. Added SessionSource::Custom(String) and --session-source.
2. Enforced plugin and skill products by session_source.
3. Applied the same filtering to curated background refresh.
This PR adds a new `thread/shellCommand` app server API so clients can
implement `!` shell commands. These commands are executed within the
sandbox, and the command text and output are visible to the model.
The internal implementation mirrors the current TUI `!` behavior.
- persist shell command execution as `CommandExecution` thread items,
including source and formatted output metadata
- bridge live and replayed app-server command execution events back into
the existing `tui_app_server` exec rendering path
This PR also wires `tui_app_server` to submit `!` commands through the
new API.
Resubmit https://github.com/openai/codex/pull/15020 with correct
content.
1. Use requirement-resolved config.features as the plugin gate.
2. Guard plugin/list, plugin/read, and related flows behind that gate.
3. Skip bad marketplace.json files instead of failing the whole list.
4. Simplify plugin state and caching.
## Summary
This PR makes `thread/resume` reuse persisted thread model metadata when
the caller does not explicitly override it.
Changes:
- read persisted thread metadata from SQLite during `thread/resume`
- reuse persisted `model` and `model_reasoning_effort` as resume-time
defaults
- fetch persisted metadata once and reuse it later in the resume
response path
- keep thread summary loading on the existing rollout path, while
reusing persisted metadata when available
- document the resume fallback behavior in the app-server README
## Why
Before this change, resuming a thread without explicit overrides derived
`model` and `model_reasoning_effort` from current config, which could
drift from the thread’s last persisted values. That meant a resumed
thread could report and run with different model settings than the ones
it previously used.
## Behavior
Precedence on `thread/resume` is now:
1. explicit resume overrides
2. persisted SQLite metadata for the thread
3. normal config resolution for the resumed cwd
1. Use requirement-resolved config.features as the plugin gate.
2. Guard plugin/list, plugin/read, and related flows behind that gate.
3. Skip bad marketplace.json files instead of failing the whole list.
4. Simplify plugin state and caching.
## Summary
- move `guardian_developer_instructions` from managed config into
workspace-managed `requirements.toml`
- have guardian continue using the override when present and otherwise
fall back to the bundled local guardian prompt
- keep the generalized prompt-quality improvements in the shared
guardian default prompt
- update requirements parsing, layering, schema, and tests for the new
source of truth
## Context
This replaces the earlier managed-config / MDM rollout plan.
The intended rollout path is workspace-managed requirements, including
cloud enterprise policies, rather than backend model metadata, Statsig,
or Jamf-managed config. That keeps the default/fallback behavior local
to `codex-rs` while allowing faster policy updates through the
enterprise requirements plane.
This is intentionally an admin-managed policy input, not a user
preference: the guardian prompt should come either from the bundled
`codex-rs` default or from enterprise-managed `requirements.toml`, and
normal user/project/session config should not override it.
## Updating The OpenAI Prompt
After this lands, the OpenAI-specific guardian prompt should be updated
through the workspace Policies UI at `/codex/settings/policies` rather
than through Jamf or codex-backend model metadata.
Operationally:
- open the workspace Policies editor as a Codex admin
- edit the default `requirements.toml` policy, or a higher-precedence
group-scoped override if we ever want different behavior for a subset of
users
- set `guardian_developer_instructions = """..."""` to the full
OpenAI-specific guardian prompt text
- save the policy; codex-backend stores the raw TOML and `codex-rs`
fetches the effective requirements file from `/wham/config/requirements`
When updating the OpenAI-specific prompt, keep it aligned with the
shared default guardian policy in `codex-rs` except for intentional
OpenAI-only additions.
## Testing
- `cargo check --tests -p codex-core -p codex-config -p
codex-cloud-requirements --message-format short`
- `cargo run -p codex-core --bin codex-write-config-schema`
- `cargo fmt`
- `git diff --check`
Co-authored-by: Codex <noreply@openai.com>
Adds an environment crate and environment + file system abstraction.
Environment is a combination of attributes and services specific to
environment the agent is connected to:
File system, process management, OS, default shell.
The goal is to move most of agent logic that assumes environment to work
through the environment abstraction.
- Add shared Product support to marketplace plugin policy and skill
policy (no enforced yet).
- Move marketplace installation/authentication under policy and model it
as MarketplacePluginPolicy.
- Rename plugin/marketplace local manifest types to separate raw serde
shapes from resolved in-memory models.
{kind=link}