## Problem
App-server clients could only initiate ChatGPT login through the browser
callback flow, even though the shared login crate already supports
device-code auth. That left VS Code, Codex App, and other app-server
clients without a first-class way to use the existing device-code
backend when browser redirects are brittle or when the client UX wants
to own the login ceremony.
## Mental model
This change adds a second ChatGPT login start path to app-server:
clients can now call `account/login/start` with `type:
"chatgptDeviceCode"`. App-server immediately returns a `loginId` plus
the device-code UX payload (`verificationUrl` and `userCode`), then
completes the login asynchronously in the background using the existing
`codex_login` polling flow. Successful device-code login still resolves
to ordinary `chatgpt` auth, and completion continues to flow through the
existing `account/login/completed` and `account/updated` notifications.
## Non-goals
This does not introduce a new auth mode, a new account shape, or a
device-code eligibility discovery API. It also does not add automatic
fallback to browser login in core; clients remain responsible for
choosing when to request device code and whether to retry with a
different UX if the backend/admin policy rejects it.
## Tradeoffs
We intentionally keep `login_chatgpt_common` as a local validation
helper instead of turning it into a capability probe. Device-code
eligibility is checked by actually calling `request_device_code`, which
means policy-disabled cases surface as an immediate request error rather
than an async completion event. We also keep the active-login state
machine minimal: browser and device-code logins share the same public
cancel contract, but device-code cancellation is implemented with a
local cancel token rather than a larger cross-crate refactor.
## Architecture
The protocol grows a new `chatgptDeviceCode` request/response variant in
app-server v2. On the server side, the new handler reuses the existing
ChatGPT login precondition checks, calls `request_device_code`, returns
the device-code payload, and then spawns a background task that waits on
either cancellation or `complete_device_code_login`. On success, it
reuses the existing auth reload and cloud-requirements refresh path
before emitting `account/login/completed` success and `account/updated`.
On failure or cancellation, it emits only `account/login/completed`
failure. The existing `account/login/cancel { loginId }` contract
remains unchanged and now works for both browser and device-code
attempts.
## Tests
Added protocol serialization coverage for the new request/response
variant, plus app-server tests for device-code success, failure, cancel,
and start-time rejection behavior. Existing browser ChatGPT login
coverage remains in place to show that the callback-based flow is
unchanged.
## Summary
This change adds websocket authentication at the app-server transport
boundary and enforces it before JSON-RPC `initialize`, so authenticated
deployments reject unauthenticated clients during the websocket
handshake rather than after a connection has already been admitted.
During rollout, websocket auth is opt-in for non-loopback listeners so
we do not break existing remote clients. If `--ws-auth ...` is
configured, the server enforces auth during websocket upgrade. If auth
is not configured, non-loopback listeners still start, but app-server
logs a warning and the startup banner calls out that auth should be
configured before real remote use.
The server supports two auth modes: a file-backed capability token, and
a standard HMAC-signed JWT/JWS bearer token verified with the
`jsonwebtoken` crate, with optional issuer, audience, and clock-skew
validation. Capability tokens are normalized, hashed, and compared in
constant time. Short shared secrets for signed bearer tokens are
rejected at startup. Requests carrying an `Origin` header are rejected
with `403` by transport middleware, and authenticated clients present
credentials as `Authorization: Bearer <token>` during websocket upgrade.
## Validation
- `cargo test -p codex-app-server transport::auth`
- `cargo test -p codex-cli app_server_`
- `cargo clippy -p codex-app-server --all-targets -- -D warnings`
- `just bazel-lock-check`
Note: in the broad `cargo test -p codex-app-server
connection_handling_websocket` run, the touched websocket auth cases
passed, but unrelated Unix shutdown tests failed with a timeout in this
environment.
---------
Co-authored-by: Eric Traut <etraut@openai.com>
### Summary
Add the v2 app-server filesystem watch RPCs and notifications, wire them
through the message processor, and implement connection-scoped watches
with notify-backed change delivery. This also updates the schema
fixtures, app-server documentation, and the v2 integration coverage for
watch and unwatch behavior.
This allows clients to efficiently watch for filesystem updates, e.g. to
react on branch changes.
### Testing
- exercise watch lifecycles for directory changes, atomic file
replacement, missing-file targets, and unwatch cleanup
- create `codex-git-utils` and move the shared git helpers into it with
file moves preserved for diff readability
- move the `GitInfo` helpers out of `core` so stacked rollout work can
depend on the shared crate without carrying its own git info module
---------
Co-authored-by: Ahmed Ibrahim <219906144+aibrahim-oai@users.noreply.github.com>
Co-authored-by: Codex <noreply@openai.com>
## Why
`shell-tool-mcp` and the Bash fork are no longer needed, but the patched
zsh fork is still relevant for shell escalation and for the
DotSlash-backed zsh-fork integration tests.
Deleting the old `shell-tool-mcp` workflow also deleted the only
pipeline that rebuilt those patched zsh binaries. This keeps the package
removal, while preserving a small release path that can be reused
whenever `codex-rs/shell-escalation/patches/zsh-exec-wrapper.patch`
changes.
## What changed
- removed the `shell-tool-mcp` workspace package, its npm
packaging/release jobs, the Bash test fixture, and the remaining
Bash-specific compatibility wiring
- deleted the old `.github/workflows/shell-tool-mcp.yml` and
`.github/workflows/shell-tool-mcp-ci.yml` workflows now that their
responsibilities have been replaced or removed
- kept the zsh patch under
`codex-rs/shell-escalation/patches/zsh-exec-wrapper.patch` and updated
the `codex-rs/shell-escalation` docs/code to describe the zsh-based flow
directly
- added `.github/workflows/rust-release-zsh.yml` to build only the three
zsh binaries that `codex-rs/app-server/tests/suite/zsh` needs today:
- `aarch64-apple-darwin` on `macos-15`
- `x86_64-unknown-linux-musl` on `ubuntu-24.04`
- `aarch64-unknown-linux-musl` on `ubuntu-24.04`
- extracted the shared zsh build/smoke-test/stage logic into
`.github/scripts/build-zsh-release-artifact.sh`, made that helper
directly executable, and now invoke it directly from the workflow so the
Linux and macOS jobs only keep the OS-specific setup in YAML
- wired those standalone `codex-zsh-*.tar.gz` assets into
`rust-release.yml` and added `.github/dotslash-zsh-config.json` so
releases also publish a `codex-zsh` DotSlash file
- updated the checked-in `codex-rs/app-server/tests/suite/zsh` fixture
comments to explain that new releases come from the standalone zsh
assets, while the checked-in fixture remains pinned to the latest
historical release until a newer zsh artifact is published
- tightened a couple of follow-on cleanups in
`codex-rs/shell-escalation`: the `ExecParams::command` comment now
describes the shell `-c`/`-lc` string more clearly, and the README now
points at the same `git.code.sf.net` zsh source URL that the workflow
uses
## Testing
- `cargo test -p codex-shell-escalation`
- `just argument-comment-lint`
- `bash -n .github/scripts/build-zsh-release-artifact.sh`
- attempted `cargo test -p codex-core`; unrelated existing failures
remain, but the touched `tools::runtimes::shell::unix_escalation::*`
coverage passed during that run
built from #14256. PR description from @etraut-openai:
This PR addresses a hole in [PR
11802](https://github.com/openai/codex/pull/11802). The previous PR
assumed that app server clients would respond to token refresh failures
by presenting the user with an error ("you must log in again") and then
not making further attempts to call network endpoints using the expired
token. While they do present the user with this error, they don't
prevent further attempts to call network endpoints and can repeatedly
call `getAuthStatus(refreshToken=true)` resulting in many failed calls
to the token refresh endpoint.
There are three solutions I considered here:
1. Change the getAuthStatus app server call to return a null auth if the
caller specified "refreshToken" on input and the refresh attempt fails.
This will cause clients to immediately log out the user and return them
to the log in screen. This is a really bad user experience. It's also a
breaking change in the app server contract that could break third-party
clients.
2. Augment the getAuthStatus app server call to return an additional
field that indicates the state of "token could not be refreshed". This
is a non-breaking change to the app server API, but it requires
non-trivial changes for all clients to properly handle this new field
properly.
3. Change the getAuthStatus implementation to handle the case where a
token refresh fails by marking the AuthManager's in-memory access and
refresh tokens as "poisoned" so it they are no longer used. This is the
simplest fix that requires no client changes.
I chose option 3.
Here's Codex's explanation of this change:
When an app-server client asks `getAuthStatus(refreshToken=true)`, we
may try to refresh a stale ChatGPT access token. If that refresh fails
permanently (for example `refresh_token_reused`, expired, or revoked),
the old behavior was bad in two ways:
1. We kept the in-memory auth snapshot alive as if it were still usable.
2. Later auth checks could retry refresh again and again, creating a
storm of doomed `/oauth/token` requests and repeatedly surfacing the
same failure.
This is especially painful for app-server clients because they poll auth
status and can keep driving the refresh path without any real chance of
recovery.
This change makes permanent refresh failures terminal for the current
managed auth snapshot without changing the app-server API contract.
What changed:
- `AuthManager` now poisons the current managed auth snapshot in memory
after a permanent refresh failure, keyed to the unchanged `AuthDotJson`.
- Once poisoned, later refresh attempts for that same snapshot fail fast
locally without calling the auth service again.
- The poison is cleared automatically when auth materially changes, such
as a new login, logout, or reload of different auth state from storage.
- `getAuthStatus(includeToken=true)` now omits `authToken` after a
permanent refresh failure instead of handing out the stale cached bearer
token.
This keeps the current auth method visible to clients, avoids forcing an
immediate logout flow, and stops repeated refresh attempts for
credentials that cannot recover.
---------
Co-authored-by: Eric Traut <etraut@openai.com>
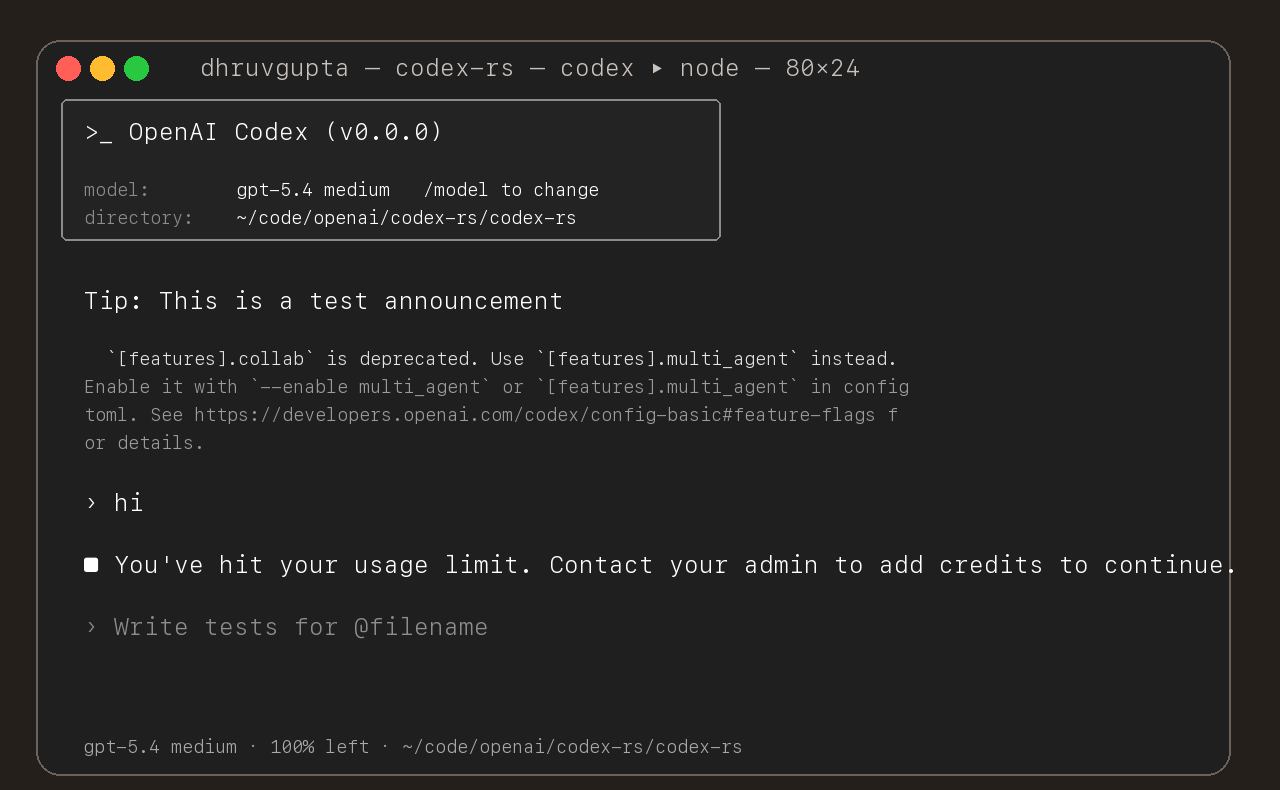
## Summary
- update the self-serve business usage-based limit message to direct
users to their admin for additional credits
- add a focused unit test for the self_serve_business_usage_based plan
branch
Added also:
If you are at a rate limit but you still have credits, codex cli would
tell you to switch the model. We shouldnt do this if you have credits so
fixed this.
## Test
- launched the source-built CLI and verified the updated message is
shown for the self-serve business usage-based plan
## Summary
- add `ForkSnapshotMode` to `ThreadManager::fork_thread` so callers can
request either a committed snapshot or an interrupted snapshot
- share the model-visible `<turn_aborted>` history marker between the
live interrupt path and interrupted forks
- update the small set of direct fork callsites to pass
`ForkSnapshotMode::Committed`
Note: this enables /btw to work similarly as Esc to interrupt (hopefully
somewhat in distribution)
---------
Co-authored-by: Codex <noreply@openai.com>
- emit a typed `thread/realtime/transcriptUpdated` notification from
live realtime transcript deltas
- expose that notification as flat `threadId`, `role`, and `text` fields
instead of a nested transcript array
- continue forwarding raw `handoff_request` items on
`thread/realtime/itemAdded`, including the accumulated
`active_transcript`
- update app-server docs, tests, and generated protocol schema artifacts
to match the delta-based payloads
---------
Co-authored-by: Codex <noreply@openai.com>
This PR add an URI-based system to reference agents within a tree. This
comes from a sync between research and engineering.
The main agent (the one manually spawned by a user) is always called
`/root`. Any sub-agent spawned by it will be `/root/agent_1` for example
where `agent_1` is chosen by the model.
Any agent can contact any agents using the path.
Paths can be used either in absolute or relative to the calling agents
Resume is not supported for now on this new path
- Split the feature system into a new `codex-features` crate.
- Cut `codex-core` and workspace consumers over to the new config and
warning APIs.
Co-authored-by: Ahmed Ibrahim <219906144+aibrahim-oai@users.noreply.github.com>
Co-authored-by: Codex <noreply@openai.com>
## Summary
Persist Stop-hook continuation prompts as `user` messages instead of
hidden `developer` messages + some requested integration tests
This is a followup to @pakrym 's comment in
https://github.com/openai/codex/pull/14532 to make sure stop-block
continuation prompts match training for turn loops
- Stop continuation now writes `<hook_prompt hook_run_id="...">stop
hook's user prompt<hook_prompt>`
- Introduces quick-xml dependency, though we already indirectly depended
on it anyway via syntect
- This PR only has about 500 lines of actual logic changes, the rest is
tests/schema
## Testing
Example run (with a sessionstart hook and 3 stop hooks) - this shows
context added by session start, then two stop hooks sending their own
additional prompts in a new turn. The model responds with a single
message addressing both. Then when that turn ends, the hooks detect that
they just ran using `stop_hook_active` and decide not to infinite loop
test files for this (unzip, move codex -> .codex):
[codex.zip](https://github.com/user-attachments/files/26075806/codex.zip)
```
› cats
• Running SessionStart hook: lighting the observatory
SessionStart hook (completed)
warning: Hi, I'm a session start hook for wizard-tower (startup).
hook context: A wimboltine stonpet is an exotic cuisine from hyperspace
• Cats are tiny zen wizards, my friend: equal parts nap, mystery, and chaos. If you want, we can talk
cat facts, cat breeds, cat names, or build something cat-themed in this repo.
• Running Stop hook: checking the tower wards
• Running Stop hook: sacking the guards
• Running Stop hook: hiring the guards
Stop hook (completed)
warning: Wizard Tower Stop hook reviewed the completed reply (177 chars).
Stop hook (blocked)
warning: Wizard Tower Stop hook continuing conversation
feedback: cook the stonpet
Stop hook (blocked)
warning: Wizard Tower Stop hook continuing conversation
feedback: eat the cooked stonpet
• Stonpet’s cooked, aloha style: flash-seared over a blue quasiflame, glazed with nebula salt, and
rested until the hyperspace juices settle.
Now we eat with gratitude, my friend. One mindful bite in, and the flavor is pure cosmic surf:
smoky, bright, and totally out of this dimension.
• Running Stop hook: checking the tower wards
• Running Stop hook: sacking the guards
• Running Stop hook: hiring the guards
Stop hook (completed)
warning: Wizard Tower Stop hook reviewed the completed reply (285 chars).
Stop hook (completed)
warning: Wizard Tower Stop hook saw a second pass and stayed calm to avoid a loop.
Stop hook (completed)
warning: Wizard Tower Stop hook saw a second pass and stayed calm to avoid a loop.
```
1. Added SessionSource::Custom(String) and --session-source.
2. Enforced plugin and skill products by session_source.
3. Applied the same filtering to curated background refresh.
This PR adds a new `thread/shellCommand` app server API so clients can
implement `!` shell commands. These commands are executed within the
sandbox, and the command text and output are visible to the model.
The internal implementation mirrors the current TUI `!` behavior.
- persist shell command execution as `CommandExecution` thread items,
including source and formatted output metadata
- bridge live and replayed app-server command execution events back into
the existing `tui_app_server` exec rendering path
This PR also wires `tui_app_server` to submit `!` commands through the
new API.
Resubmit https://github.com/openai/codex/pull/15020 with correct
content.
1. Use requirement-resolved config.features as the plugin gate.
2. Guard plugin/list, plugin/read, and related flows behind that gate.
3. Skip bad marketplace.json files instead of failing the whole list.
4. Simplify plugin state and caching.
1. Use requirement-resolved config.features as the plugin gate.
2. Guard plugin/list, plugin/read, and related flows behind that gate.
3. Skip bad marketplace.json files instead of failing the whole list.
4. Simplify plugin state and caching.
- Add shared Product support to marketplace plugin policy and skill
policy (no enforced yet).
- Move marketplace installation/authentication under policy and model it
as MarketplacePluginPolicy.
- Rename plugin/marketplace local manifest types to separate raw serde
shapes from resolved in-memory models.
- route realtime startup, input, and transport failures through a single
shutdown path
- emit one realtime error/closed lifecycle while clearing session state
once
---------
Co-authored-by: Codex <noreply@openai.com>
Co-authored-by: Ahmed Ibrahim <219906144+aibrahim-oai@users.noreply.github.com>
- thread the realtime version into conversation start and app-server
notifications
- keep playback-aware mic gating and playback interruption behavior on
v2 only, leaving v1 on the legacy path
## What is flaky
`codex-rs/app-server/tests/suite/fuzzy_file_search.rs` intermittently
loses the expected `fuzzyFileSearch/sessionUpdated` and
`fuzzyFileSearch/sessionCompleted` notifications when multiple
fuzzy-search sessions are active and CI delivers notifications out of
order.
## Why it was flaky
The wait helpers were keyed only by JSON-RPC method name.
- `wait_for_session_updated` consumed the next
`fuzzyFileSearch/sessionUpdated` notification even when it belonged to a
different search session.
- `wait_for_session_completed` did the same for
`fuzzyFileSearch/sessionCompleted`.
- Once an unmatched notification was read, it was dropped permanently
instead of buffered.
- That meant a valid completion for the target search could arrive
slightly early, be consumed by the wrong waiter, and disappear before
the test started waiting for it.
The result depended on notification ordering and runner scheduling
instead of on the actual product behavior.
## How this PR fixes it
- Add a buffered notification reader in
`codex-rs/app-server/tests/common/mcp_process.rs`.
- Match fuzzy-search notifications on the identifying payload fields
instead of matching only on method name.
- Preserve unmatched notifications in the in-process queue so later
waiters can still consume them.
- Include pending notification methods in timeout failures to make
future diagnosis concrete.
## Why this fix fixes the flakiness
The test now behaves like a real consumer of an out-of-order event
stream: notifications for other sessions stay buffered until the correct
waiter asks for them. Reordering no longer loses the target event, so
the test result is determined by whether the server emitted the right
notifications, not by which one happened to be read first.
Co-authored-by: Ahmed Ibrahim <219906144+aibrahim-oai@users.noreply.github.com>
Co-authored-by: Codex <noreply@openai.com>
## Stack Position
2/4. Built on top of #14828.
## Base
- #14828
## Unblocks
- #14829
- #14827
## Scope
- Port the realtime v2 wire parsing, session, app-server, and
conversation runtime behavior onto the split websocket-method base.
- Branch runtime behavior directly on the current realtime session kind
instead of parser-derived flow flags.
- Keep regression coverage in the existing e2e suites.
---------
Co-authored-by: Codex <noreply@openai.com>
- Added forceRemoteSync to plugin/install and plugin/uninstall.
- With forceRemoteSync=true, we update the remote plugin status first,
then apply the local change only if the backend call succeeds.
- Kept plugin/list(forceRemoteSync=true) as the main recon path, and for
now it treats remote enabled=false as uninstall. We
will eventually migrate to plugin/installed for more precise state
handling.
This extends dynamic_tool_calls to allow us to hide a tool from the
model context but still use it as part of the general tool calling
runtime (for ex from js_repl/code_mode)
make plugins' `defaultPrompt` an array, but keep backcompat for strings.
the array is limited by app-server to 3 entries of up to 128 chars
(drops extra entries, `None`s-out ones that are too long) without
erroring if those invariants are violating.
added tests, tested locally.
We regularly get bug reports from users who mistakenly have the
`OPENAI_BASE_URL` environment variable set. This PR deprecates this
environment variable in favor of a top-level config key
`openai_base_url` that is used for the same purpose. By making it a
config key, it will be more visible to users. It will also participate
in all of the infrastructure we've added for layered and managed
configs.
Summary
- introduce the `openai_base_url` top-level config key, update
schema/tests, and route the built-in openai provider through it while
- fall back to deprecated `OPENAI_BASE_URL` env var but warn user of
deprecation when no `openai_base_url` config key is present
- update CLI, SDK, and TUI code to prefer the new config path (with a
deprecated env-var fallback) and document the SDK behavior change
## Summary
- add `approvals_reviewer = "user" | "guardian_subagent"` as the runtime
control for who reviews approval requests
- route Smart Approvals guardian review through core for command
execution, file changes, managed-network approvals, MCP approvals, and
delegated/subagent approval flows
- expose guardian review in app-server with temporary unstable
`item/autoApprovalReview/{started,completed}` notifications carrying
`targetItemId`, `review`, and `action`
- update the TUI so Smart Approvals can be enabled from `/experimental`,
aligned with the matching `/approvals` mode, and surfaced clearly while
reviews are pending or resolved
## Runtime model
This PR does not introduce a new `approval_policy`.
Instead:
- `approval_policy` still controls when approval is needed
- `approvals_reviewer` controls who reviewable approval requests are
routed to:
- `user`
- `guardian_subagent`
`guardian_subagent` is a carefully prompted reviewer subagent that
gathers relevant context and applies a risk-based decision framework
before approving or denying the request.
The `smart_approvals` feature flag is a rollout/UI gate. Core runtime
behavior keys off `approvals_reviewer`.
When Smart Approvals is enabled from the TUI, it also switches the
current `/approvals` settings to the matching Smart Approvals mode so
users immediately see guardian review in the active thread:
- `approval_policy = on-request`
- `approvals_reviewer = guardian_subagent`
- `sandbox_mode = workspace-write`
Users can still change `/approvals` afterward.
Config-load behavior stays intentionally narrow:
- plain `smart_approvals = true` in `config.toml` remains just the
rollout/UI gate and does not auto-set `approvals_reviewer`
- the deprecated `guardian_approval = true` alias migration does
backfill `approvals_reviewer = "guardian_subagent"` in the same scope
when that reviewer is not already configured there, so old configs
preserve their original guardian-enabled behavior
ARC remains a separate safety check. For MCP tool approvals, ARC
escalations now flow into the configured reviewer instead of always
bypassing guardian and forcing manual review.
## Config stability
The runtime reviewer override is stable, but the config-backed
app-server protocol shape is still settling.
- `thread/start`, `thread/resume`, and `turn/start` keep stable
`approvalsReviewer` overrides
- the config-backed `approvals_reviewer` exposure returned via
`config/read` (including profile-level config) is now marked
`[UNSTABLE]` / experimental in the app-server protocol until we are more
confident in that config surface
## App-server surface
This PR intentionally keeps the guardian app-server shape narrow and
temporary.
It adds generic unstable lifecycle notifications:
- `item/autoApprovalReview/started`
- `item/autoApprovalReview/completed`
with payloads of the form:
- `{ threadId, turnId, targetItemId, review, action? }`
`review` is currently:
- `{ status, riskScore?, riskLevel?, rationale? }`
- where `status` is one of `inProgress`, `approved`, `denied`, or
`aborted`
`action` carries the guardian action summary payload from core when
available. This lets clients render temporary standalone pending-review
UI, including parallel reviews, even when the underlying tool item has
not been emitted yet.
These notifications are explicitly documented as `[UNSTABLE]` and
expected to change soon.
This PR does **not** persist guardian review state onto `thread/read`
tool items. The intended follow-up is to attach guardian review state to
the reviewed tool item lifecycle instead, which would improve
consistency with manual approvals and allow thread history / reconnect
flows to replay guardian review state directly.
## TUI behavior
- `/experimental` exposes the rollout gate as `Smart Approvals`
- enabling it in the TUI enables the feature and switches the current
session to the matching Smart Approvals `/approvals` mode
- disabling it in the TUI clears the persisted `approvals_reviewer`
override when appropriate and returns the session to default manual
review when the effective reviewer changes
- `/approvals` still exposes the reviewer choice directly
- the TUI renders:
- pending guardian review state in the live status footer, including
parallel review aggregation
- resolved approval/denial state in history
## Scope notes
This PR includes the supporting core/runtime work needed to make Smart
Approvals usable end-to-end:
- shell / unified-exec / apply_patch / managed-network / MCP guardian
review
- delegated/subagent approval routing into guardian review
- guardian review risk metadata and action summaries for app-server/TUI
- config/profile/TUI handling for `smart_approvals`, `guardian_approval`
alias migration, and `approvals_reviewer`
- a small internal cleanup of delegated approval forwarding to dedupe
fallback paths and simplify guardian-vs-parent approval waiting (no
intended behavior change)
Out of scope for this PR:
- redesigning the existing manual approval protocol shapes
- persisting guardian review state onto app-server `ThreadItem`s
- delegated MCP elicitation auto-review (the current delegated MCP
guardian shim only covers the legacy `RequestUserInput` path)
---------
Co-authored-by: Codex <noreply@openai.com>
Add a protocol-level filesystem surface to the v2 app-server so Codex
clients can read and write files, inspect directories, and subscribe to
path changes without relying on host-specific helpers.
High-level changes:
- define the new v2 fs/readFile, fs/writeFile, fs/createDirectory,
fs/getMetadata, fs/readDirectory, fs/remove, fs/copy RPCs
- implement the app-server handlers, including absolute-path validation,
base64 file payloads, recursive copy/remove semantics
- document the API, regenerate protocol schemas/types, and add
end-to-end tests for filesystem operations, copy edge cases
Testing plan:
- validate protocol serialization and generated schema output for the
new fs request, response, and notification types
- run app-server integration coverage for file and directory CRUD paths,
metadata/readDirectory responses, copy failure modes, and absolute-path
validation
{kind=link}